Using a lot of mails.
✉️ Sourcing Large Scale Email Data
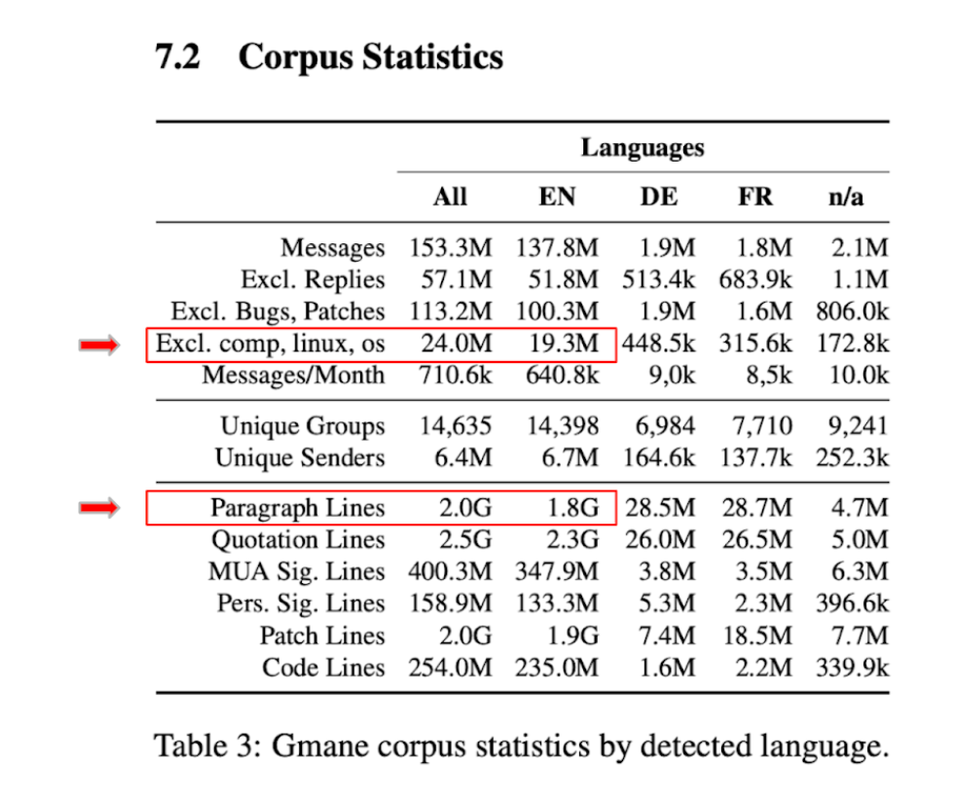
In order to write intro & extroverted mail texts, we need mail data as a base. The problem about mails is that they are usually highly personal or proprietary which is why there is little available. While you can crawl a forum or a chat to get data it is hard to collect mail data. There is some publicly available mail datasets since the leakage of the Enron email dataset upon its scandal in 2001 or the leakage of Hillary Clinton’s personal emails in the context of the 2016 US presidential elections, but there quality, timeliness and quantity is rather little. Yet, the German team behind webis.de compiled a large scale dataset consisting of 153M emails that got scraped from the GMANE mailing lists. While there is a lot of mails relating to computer, os or linux issues, a few million (24.3M) are in more non-technological domains like history, arts, music or business. A statistical overview can be found on the right. The entirety of the data comes in a nested json structure, that needs parsing and pre-processing to be useful. This step is always needed, and there are different packages that can be used to work with. Out of preference, the author uses Python Pandas on a Google Colab Infrastructure in the following.
 ](https://postimg.cc/KRcyCHPL)
](https://postimg.cc/KRcyCHPL)
An exemplary email 📃
Before exploring the structure of the entire dataset, we look on a single mail to get an overview. The raw email text that is of interest to us is composed of the: salutation, paragraph and closing (see red rectangular). Other visible aspects are the quotation of the previous text and the message signature. The quotation (quot) may prove useful to evaluate the relation between the two communicators and to understand the perception of the quoted message (think of analysing the degree of positiveness, politeness or acceptance from the responders email). Visual markers such as the separators (sep) or the tech may also not be of interest for creating an initial email dataset but could be revisited later. We do not see much value in evaluating the message signature (msig) since it is usually pre-compiled and not written by a human.
 ](https://postimg.cc/2L8X9gsS)
](https://postimg.cc/2L8X9gsS)
Getting a Data Overview
Before writing the first line of code, we take a brief look at all the different columns names (i.e. headers) available and get a bird’s eye view of the data we are dealing with. (1) Starting from the highest nesting level ‘Available Columns’ allows us to filter the language we are interested in (en) and allows us to get the groups (i.e., domains in which text is written) that we are actually interested in (e.g., arts, history, business, money). This step drastically reduces the amount of relevant mails to process (since we exclude major topics such as os). Obviously, we want to consider the text_plain as the core of our dataset. (2) Next, we choose our mail headers, such as subject, from, to, and most importantly the boolean value ‘in_reply_to‘ to identify the perception of a mail (see previous slide). (3) Last, we select all the segments that are of importance to us, such as paragraph, closing, salutation, to get the plain text. Further segments such as quotation may also be of interest. More on that in the excursus: ‘export mail-response pairs’.
 ](https://postimg.cc/68Rzc98h)
](https://postimg.cc/68Rzc98h)
Parsing .json
At this level the coding section starts, and albeit the introduction part is left out (importing packages, connecting to Google Drive), and reading the json files in, and concatenating them to a pandas dataframe. Yet, we only have the nested structure of the json files, so they need to be flattened.
Tricky! It is important that we only get the actual email bodies from salutation to ending (e.g., salutation, paragraph, table, paragraph, ending), since they only contain human written sentences. The trick is to use the string start and end indicators from the segments and to apply them to the plain text. The illustration in the lower left sketches the idea behind it. The parsing happened up to a nesting level of 6, since that was considered to be simple enough mails (and also allowed not to run out of the 32 GB RAM of Google Colab). Batching would have helped to prevent that but it resulted in enough data.
 ](https://postimg.cc/p9c9njPc)
](https://postimg.cc/p9c9njPc)
💿 Sentence-level Email Data
The objective is to get properly written email styled sentences that are below 512 tokens length. These shall be linguistically and semantically correct under the consideration of the following aspects:
- The casing shall be correct.
- Correct verb inflections and number of persons with adjectives, nouns, adverbs, etc.
- Punctuations shall be recognized.
- All code, and non alphanumeric sentences are removed (extensive use of #### or %$#%@&*# shall not happen.
- Duplicates should be removed.
- Extensively long, and very short three word sentences have to be excluded.
- All text fragments are on sentence levels.
Therefore, replacements, regex cleanups, and the splitting into sentences based on the statistical model of SpaCy is conducted. Since we are dealing with millions of sentences, it helps to parallelize and batch this process.
💥 Some Data Augmentation Secrets
Lastly, we are going to add some natural language processing sugar to our already almost picture perfect email dataset. Up until now, we have not accounted for spelling errors, and semantic and syntactic correctness in our dataset. Luckily, there is ways to outsource and double check these. While I was using Jamspell earlier to correct for spelling mistakes, I encountered GingerIT which offers an API that deals with erroneous writing inconsistencies such as:
- Casing
- Verb inflections
- Tense
- Pluralization
- Spelling
However, their API is slow (processing a sentence takes roughly one second each and we are processing 1.1M). Therefore, it is helpful to parallelize the process by splitting the dataframe into multiple ones, and parallelizing the data processing. With a factor of 16, I achieved the transformation of the entire dataset in under 24 hours.
Besides, running all sentences through the a distillbert deep neural net that is fine-tuned on the CoLA dataset allows us to get a rating in between 0 and 1, relating to the semantic and syntactic correctness of each sentence.